
Could it be the north wind they’d been feelin’?”
“The Wreck Of The Edmund Fitzgerald”
— Gordon Lightfoot
At my home, I’m using a Raspberry Pi as a watchdog (aptly named “Brutus”) for all kinds of tasks: burglar detection, network intrusion detection, and server monitoring, just to name a few. Still, most of the time, my watchdog hangs around, idling away. That’s not the way I like it, so I’m constantly on the lookout for new jobs that I can assign to Brutus, small or big.
My current plan is to create a little ship’s bell app that emits pleasing bell sounds every 30 minutes, just like it has been done traditionally on all ships since the 16th century: double-strikes for full hours and an additional single-strike for half an hour. But unlike civil clocks, ship’s bells don’t have dedicated indications for every one of the 12 (or rather 24) hours in a day; instead, bell patterns repeat every four hours:
| Bell pattern | Time (a.m. and p.m.) | ||
| 1 | 12:30 | 4:00 | 8:00 |
| 2 | 1:00 | 5:00 | 9:00 |
| 2 1 | 1:30 | 5:30 | 9:30 |
| 2 2 | 2:00 | 6:00 | 10:00 |
| 2 2 1 | 2:30 | 6:30 | 10:30 |
| 2 2 2 | 3:00 | 7:00 | 11:00 |
| 2 2 2 1 | 3:30 | 7:30 | 11:30 |
| 2 2 2 2 | 4:00 | 8:00 | 12:00 |
The code below is a first draft of my ship’s bell app. It is running as a thread, sleeping most of the time (so you can still call Brutus a lazy dog). When it wakes up, it checks the current local time and determines how many strikes are to be done (‘compute_strikes’). Afterwards, the thread puts itself to rest again. However, I didn’t want to wake it up every second to check the wall time — that would be too inefficient. Instead, I base the sleep time on the temporal distance between now and the next half hour (‘compute_sleep_time’) and sleep for half of this time before checking again.
Alas, my initial implementation comes with a bug and the bell doesn’t work as it is supposed to. Can you spot it? (The bug is in the algorithm — it has nothing to do with any Python language quirks, of course.)

 Last month,
Last month, 

 According to an old saying, there’s more than one way to skin a cat. There are at least as many ways to compute the value of π. One of them uses the
According to an old saying, there’s more than one way to skin a cat. There are at least as many ways to compute the value of π. One of them uses the 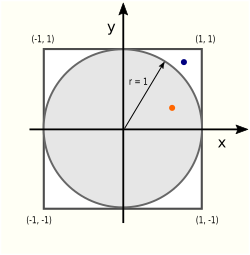 There are two areas (literally!) of interest in this picture: the circle area Ac and the square area As:
There are two areas (literally!) of interest in this picture: the circle area Ac and the square area As: