
— Kim Collins
Checking in early and often is a well-accepted practice these days. Instead of keeping changes local for an extended period of time, software is continuously integrated and thus the overall integration risk is significantly reduced because every time you check into the central repository, your changes become immediately visible and available to others. Problems show up early, which is for sure a good thing.
On the other hand, your code must have a certain level of quality before you can foist it upon others. At the very least, it must compile without errors. Most likely, it is also required to be in line with other project or coding standards, for instance, code must be free of compiler (or MISRA) warnings. Some projects even demand that every code that is checked-in has been 100% code-coverage tested.
Having such “pre-commit quality gates” is a blessing but it stands in the way of the “commit early, commit often” paradigm: Depending on the size of the task it may take hours (if not days) to meet all check-in criteria. Deferring commits for such a long time would certainly be foolish because check-ins are important for another reason: With every commit you drive in a piton that not only saves you from data loss but also allows you to go back and forth in time.
Fortunately, with distributed version control systems like Git, you can check in locally at your heart’s content without affecting others. When your code is nice and shiny (and is in line with your project standards), you integrate it by “pushing” to the central repository. I love to work like this!
Often, I check in every couple of minutes, sometimes even though my code doesn’t compile yet. Maybe after some minutes of tedious editing, only to ensure that my changes are not lost. Just like Hansel and Gretel, I like to leave bread crumbs behind, but unlike theirs, mine won’t be eaten by the birds.
The hard part is deciding on a commit message, though. I don’t want to break my flow by thinking about something suitable. Many times, the changes are not even coherent, so the commit messages cannot be meaningful. What’s my solution? I simply run
|
1 2 3 |
git add -A && git commit -m "Checkpoint" |
over and over again.
As you can imagine, there will be dozens of “checkpoints” before I’m finished with my high-level task. Consequently, the commit history (what git log shows) is an utter mess. Even though Git supports various commands to alter the commit history (git rebase -i, for example), doing it manually is both, tedious and error-prone. I therefore decided to automate this process through a little tool named git-autocommit.
git-autocommit is a short Bash script that you invoke in your working directory. It runs indefinitely (at least until you hit Ctrl-C) and periodically executes git add -A && git commit -m "<git-autocommit>". When you’re done with your changes, you hit Ctrl-C and run git-autocommit again. Then, the script checks if there is a series of <git-autocommit> commit messages already at the top of your commit history and if so, performs a soft reset to the predecessor of the first autocommit; otherwise, it just waits for new changes in your working directory and autocommits them as before.
The upshot of this is that all the changes that you’ve done (those changes that have been autocommitted) are now staged and ready to be committed again, but this time en bloc and with a descriptive check-in comment. Once checked-in, all the intermediate autocommits are gone from the log and it looks as if you’ve made a perfect sausage.

 According to an old saying, there’s more than one way to skin a cat. There are at least as many ways to compute the value of π. One of them uses the
According to an old saying, there’s more than one way to skin a cat. There are at least as many ways to compute the value of π. One of them uses the 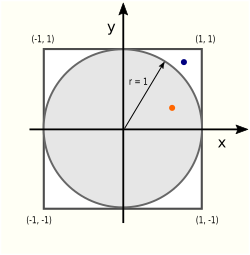 There are two areas (literally!) of interest in this picture: the circle area Ac and the square area As:
There are two areas (literally!) of interest in this picture: the circle area Ac and the square area As: Two months ago, I
Two months ago, I  I quite remember the uneasy sensation that I had when a former coworker told me a story — a story about a senior engineer who went to jail because of a bug, a fatal one, as it turned out.
I quite remember the uneasy sensation that I had when a former coworker told me a story — a story about a senior engineer who went to jail because of a bug, a fatal one, as it turned out.{kind=link}